Cross Validation¶
As time-series have the inherent structure we could run into problems with traditional shuffled Kfolds cross-validation. hcrystalball implements forward rolling cross-validation making training set consist only of observations that occurred prior to the observations that form the test set.

[1]:
from hcrystalball.model_selection import FinerTimeSplit
from sklearn.model_selection import cross_validate
from hcrystalball.wrappers import ExponentialSmoothingWrapper
[2]:
import pandas as pd
import matplotlib.pyplot as plt
# plt.style.use('fivethirtyeight')
plt.rcParams['figure.figsize'] = [12, 6]
[3]:
from hcrystalball.utils import get_sales_data
df = get_sales_data(n_dates=100,
n_assortments=1,
n_states=1,
n_stores=1)
X, y = pd.DataFrame(index=df.index), df['Sales']
Native Cross Validation¶
[4]:
cross_validate(ExponentialSmoothingWrapper(),
X,
y,
cv=FinerTimeSplit(horizon=5, n_splits=2),
scoring='neg_mean_absolute_error')
[4]:
{'fit_time': array([0.00762606, 0.00661516]),
'score_time': array([0.00789881, 0.00755548]),
'test_score': array([-4822.51813324, -5489.07012375])}
Grid search and model selection¶
Model selection and parameter tuning is the area where hcrystalball really shines. There is ongoing and probably a never-ending discussion about superiority or inferiority of ML techniques over common statistical/econometrical ones. Why not try both? The problem of a simple comparison between the performance of different kind of algorithms such as SARIMAX, Prophet, regularized linear models, and XGBoost lead to hcrystalball. Let’s see how to do it!
[5]:
from hcrystalball.compose import TSColumnTransformer
from hcrystalball.feature_extraction import SeasonalityTransformer
from hcrystalball.wrappers import ProphetWrapper
from hcrystalball.wrappers import get_sklearn_wrapper
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
from hcrystalball.wrappers import SarimaxWrapper
from sklearn.model_selection import GridSearchCV
import numpy as np
import pandas as pd
Define our pipeline¶
[6]:
sklearn_model_pipeline = Pipeline([
('seasonality', SeasonalityTransformer(freq='D')),
('model', 'passthrough') # this will be overwritten by param grid
])
Define pipeline parameters including different models¶
[7]:
param_grid = [{'model': [sklearn_model_pipeline],
'model__model':[get_sklearn_wrapper(RandomForestRegressor),
get_sklearn_wrapper(LinearRegression)]},
{'model': [ProphetWrapper()],
'model__seasonality_mode':['multiplicative', 'additive']},
{'model': [SarimaxWrapper(order=(2,1,1), suppress_warnings=True)]}
]
Run native grid search¶
[8]:
grid_search = GridSearchCV(estimator=sklearn_model_pipeline,
param_grid=param_grid,
scoring='neg_mean_absolute_error',
cv=FinerTimeSplit(horizon=5, n_splits=2),
refit=False,
error_score=np.nan)
[9]:
results = grid_search.fit(X, y)
[10]:
pd.DataFrame(results.cv_results_).sort_values('rank_test_score').head()
[10]:
| mean_fit_time | std_fit_time | mean_score_time | std_score_time | param_model | param_model__model | param_model__seasonality_mode | params | split0_test_score | split1_test_score | mean_test_score | std_test_score | rank_test_score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.022898 | 0.002637 | 0.066595 | 0.008093 | (SeasonalityTransformer(auto=True, freq='D', m... | SklearnWrapper(clip_predictions_lower=None, cl... | NaN | {'model': (SeasonalityTransformer(auto=True, f... | -1263.234636 | -1466.042533 | -1364.638585 | 101.403949 | 1 |
| 0 | 0.023838 | 0.001489 | 0.351573 | 0.004944 | (SeasonalityTransformer(auto=True, freq='D', m... | SklearnWrapper(bootstrap=True, ccp_alpha=0.0, ... | NaN | {'model': (SeasonalityTransformer(auto=True, f... | -1953.182000 | -1770.338000 | -1861.760000 | 91.422000 | 2 |
| 2 | 1.264993 | 0.666760 | 2.625766 | 0.051198 | ProphetWrapper(changepoint_prior_scale=0.05, c... | NaN | multiplicative | {'model': ProphetWrapper(changepoint_prior_sca... | -2601.205624 | -1407.257183 | -2004.231404 | 596.974220 | 3 |
| 3 | 0.469486 | 0.024832 | 2.620793 | 0.040178 | ProphetWrapper(changepoint_prior_scale=0.05, c... | NaN | additive | {'model': ProphetWrapper(changepoint_prior_sca... | -2687.583938 | -1330.634452 | -2009.109195 | 678.474743 | 4 |
| 4 | 1.328611 | 0.018301 | 0.054028 | 0.002102 | SarimaxWrapper(always_search_model=False, auto... | NaN | NaN | {'model': SarimaxWrapper(always_search_model=F... | -1121.758965 | -14636.329937 | -7879.044451 | 6757.285486 | 5 |
It seems that the best model is sklearn with RandomForestRegressor, but in time-series, it is often also a good idea to check how the forecasts look like. Unfortunately, this is not possible with sklearn. grid_search is returning just the results, not the predictions of individual models for different splits. hcrystalball thus implements special scoring functions that track all data from the grid_search.
Custom scorer¶
[11]:
from hcrystalball.metrics import make_ts_scorer
from sklearn.metrics import mean_absolute_error
[12]:
scoring = make_ts_scorer(mean_absolute_error,
greater_is_better=False)
[13]:
grid_search = GridSearchCV(estimator=sklearn_model_pipeline,
param_grid=param_grid,
scoring=scoring,
cv=FinerTimeSplit(horizon=5, n_splits=2),
refit=False,
error_score=np.nan)
results = grid_search.fit(X, y)
[14]:
results.scorer_.cv_data.loc[:,lambda x: x.columns != 'split'].plot();
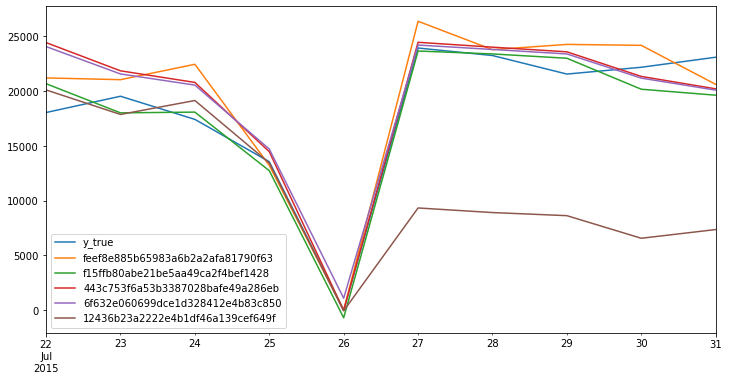
hcrystalball internally tracks data based on unique model hashes since model string represantations (reprs) are very long for usable columns names in dataframe, but if you are curious i.e. what was the worse model not to use it for further experiment, you can do it with scorers estimator_ids attribute
[15]:
results.scorer_.cv_data.head()
[15]:
| split | y_true | feef8e885b65983a6b2a2afa81790f63 | f15ffb80abe21be5aa49ca2f4bef1428 | 443c753f6a53b3387028bafe49a286eb | 6f632e060699dce1d328412e4b83c850 | 12436b23a2222e4b1df46a139cef649f | |
|---|---|---|---|---|---|---|---|
| 2015-07-22 | 0 | 18046.0 | 21204.96 | 20676.741135 | 24428.095232 | 24065.094696 | 20108.463667 |
| 2015-07-23 | 0 | 19532.0 | 21044.02 | 18015.494274 | 21852.187052 | 21566.265711 | 17871.040123 |
| 2015-07-24 | 0 | 17420.0 | 22448.20 | 18084.973453 | 20794.186777 | 20548.954160 | 19143.531055 |
| 2015-07-25 | 0 | 13558.0 | 13223.18 | 12739.066714 | 14475.237140 | 14713.923592 | 13445.097910 |
| 2015-07-26 | 0 | 0.0 | 0.00 | -685.019580 | -12.321919 | 1099.681532 | -48.938135 |
We can get to the model definitions using hash in results.scorer_.estimator_ids dict